This post is a bit of an overview or primer on all things related to releasing and deploying new versions of software, be it a product (e.g., a WordPress plugin, or an npm or Composer package) or an entire project website. I thought about writing this post for quite a while, due to recurring discussions about one or the other of those things, and also because of a fairly well-rounded overall release-and-deployment process that my current project team has refined over the last year or so.
Version Control
When working on software projects, you should be using some form of version control system (VCS), which allows you to keep track of all the changes made to your software over time. For pretty much everything at Human Made, we are using Git as our VCS of choice, which is why I will focus on Git for the remainder of this post.
Using Git, a change applied to the codebase is called a commit. This can be a single change to a single file, or lots of changes to hundreds of files, all committed as one changeset.
gitglossary Documentation
commit
A single point in the Git history; the entire history of a project is represented as a set of interrelated commits.
Commits are identified or referenced by a unique hash that Git automatically generates. Each commit usually has a user-defined message attached, intended for describing the (type of) change.
Tags
In addition to the unique, automatic hashes, it is possible to refer to a commit by means of a user-defined tag.
gitglossary Documentation
tag
A ref underrefs/tags/namespace that points to an object of an arbitrary type (typically a tag points to either a tag or a commit object). […] A tag is most typically used to mark a particular point in the commit ancestry chain.
A tag is pretty much an alias for or a free-form text reference to an existing commit, going beyond the meaningless hash. Tags are usually used to mark versions or otherwise meaningful states of software.
Versions
Given that each commit represents a snapshot of your entire codebase, it also is a version of your software. However, usually, when people refer to “version”, they are talking about a deliberately released, that is, documented and announced snapshot.
Versions should follow a clearly defined standard. The most well-known and also adopted one is called Semantic Versioning, or short: SemVer. All Altis modules follow SemVer, plus lots of other plugin and library repositories. (You should, too!)
A version can be stable—usually using regular numbered identifiers—or a pre-release version—something like 1.2.0-beta or 2.0.0-rc.2—which allows testing the upcoming stable version early.
When using a Git repository as source for an npm or Composer package, any commit (hash) can serve as version reference. Also, tags will automatically appear as available versions of the package, as well as branches.
Changelogs
Any new version of your software should ideally be accompanied by some form of changelog (entry). This is a list of high-level changes that have been introduced as part of the version, considering the immediately preceding version.
A changelog is a log or record of all notable changes made to a project. The project is often a website or software project, and the changelog usually includes records of changes such as bug fixes, new features, etc.
Wikipedia
Such a changelog can exist in multiple forms and shapes, it can have different audiences (e.g., technical-minded people or fellow engineers vs. potentially non-technical end users vs. other people in the business), can have varying levels of detail. The changelog can live within the software, or it can be somewhere else, for example, on the project or product website, or in other tools such as Confluence or a Wiki.
One more well-known standard or approach to doing changelogs is Keep a Changelog. Some important aspects include chronologically ordering versions, including the release date, grouping changes according to their type, and mentioning what has changed. You definitely can include how and why, but the What is key.
Sometimes, people (try to) use the commit messages for this. More often than not, however, this simply doesn’t work, for various reasons. Another way to go about this is to squash all commits in a PR into a single commit with a meaningful commit message. While this works much better than surfacing every single original commit message, it comes with other problems. A third way is to use either pull request or ticket titles for this. Personally, I think one should actually write changelogs. With the intended audience in mind, providing the right (amount of) information, in the right way.
Releases
Oftentimes, you will find “version” and “release” being used interchangeably. To me, however, a new release includes (or accompanies) a new version. But there’s more.
Releasing a new version of some piece of software, to me, means preparing and cutting the new version—which is just the code, creating or updating the changelog, potentially documenting select relevant pieces of what has changed, maybe including how and why you would be using, seeing or otherwise experiencing these changes, and overall actively announcing and advertizing the new version.
GitHub Releases
A lot of more modern projects are using GitHub, so you might already know that Releases are an actual thing on GitHub. There have been several discussions about when and why you might want to use the GitHub Releases functionality. So I thought I’d give a quick run-down of my own thinking about that.
Disclaimer: Please note that Releases is something that GitHub have worked on continuously for quite a while. So, depending on when you might read this post, things could look or be different, or live somewhere else.
Creating a GitHub Release
Releases on GitHub are based on a tag. When drafting a new release, you can either select an existing tag, or define the tag that you want to have created when you publish the release.
The release body can be anything you want, but its main purpose is to include the changelog. GitHub refers to this as “release notes”, and you can actually generate release notes by clicking the “Generate release notes” button on this screen. By default, this is based on the titles of all merged pull requests, but this can be configured in various ways.
If you want, you can also supply additional asset files for the release, for example, compiled binaries, or PDF files as documentation or whatnot.
Browsing GitHub Releases
Right on the repository screen, you see releases prominently exposed in the sidebar, showing the most recent version. (GitHub also supports pre-releases.)
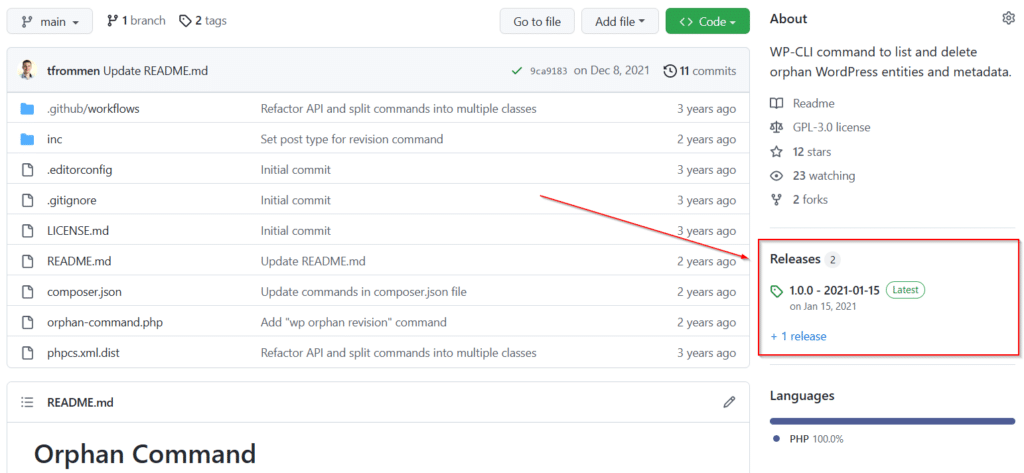
The Releases page then lists all previous (and draft) releases, providing some more metadata such as the author of the release, the respective Git tag and commit (all linked), and it allows to easily compare the release (head commit) with any other tag (or hash) right from the sidebar UI.
In case you mention GitHub usernames in a release, GitHub will automatically render a nice little Contributors section.
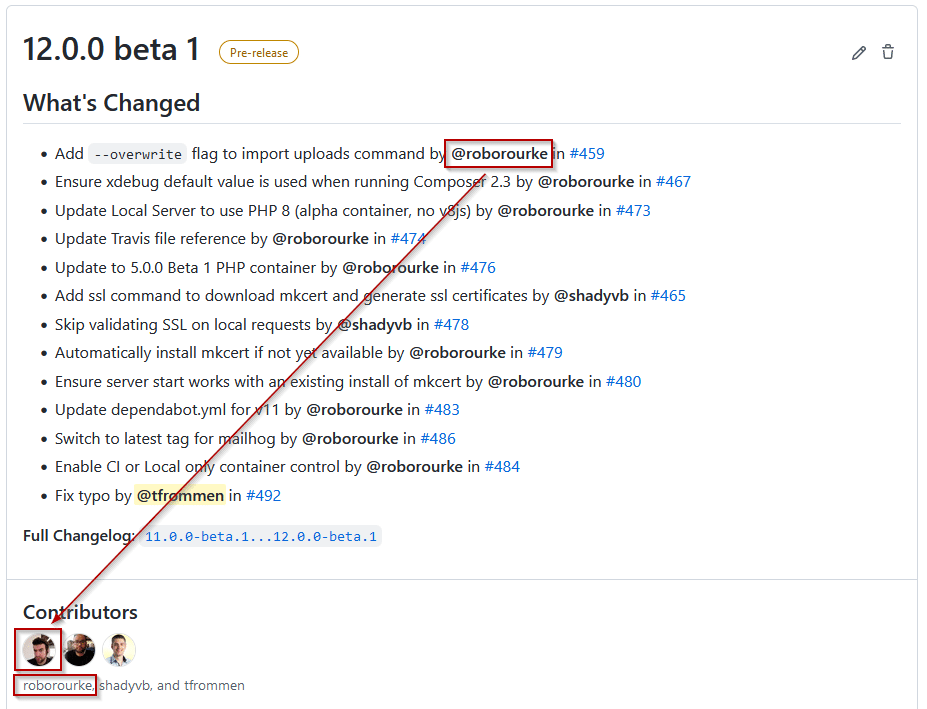
Looking at a single release, you will see the exact same information, slightly differently styled, plus a handy link to the (number of) changes made to the branch you selected for the release, since publishing it.

Overall, GitHub Releases means “upgrading” a Git tag, representing a version of your codebase, to a much more complete release experience, integrating changelog, additional user-defined content and asset files (if required), and interlinking all the things already available on GitHub. I love GitHub Releases!
Deployments
If you are working on a project website, you not only need to do feature development, fix some bugs, update inline documentation etc. and release a new version of the website codebase, you also have to actually get that version onto that project’s webserver(s); you need to deploy the new version.
Let’s assume a project that has a dedicated Git branch configured for each environment. These branches will be used to pull the latest available version of the project codebase. Deploying the new version, on a technical level, is as simple as this:
- Ensure the branch selected for the Production (or other) environment includes the new code.
- Deploy the new code.
Besides the code level, releasing and deploying a new version of a project website might also include some additional steps. Those might be related to governance, reporting passing tests and/or software analysis runs, or adhering to any other client-side requirements. Finally, you might have to get sign-off from a key stakeholder. Where possible, I suggest documenting, as well as automating as much as possible of the overall process.
Depending on your branching strategy and additional steps included in your release/deployment process, you might have to refresh your main branch with the latest release.
Leave a Reply